Visualizing Prophet's changepoint.prior.scale
Dec 2018 · 1206 words · 6 minutes read

As a followup to my post about visualizing Prophet Forecast Output, this post will do the same process of combing purrr/furrr and prophet to run a lot of forecasts in a more structured way and then visualizing the results with gganimate.
The purpose of this post will be to provide a range of input values to the changepoint.prior.scale parameter and observe what it does to Prophet’s forecast and it’s confidence intervals. The output will be the gif at the top of this post.
Step 1: Fetch Data
We will use the same data we used in the first post, the number of en.wikipedia.org pageviews by day since October 2015
library( 'pageviews')
library( 'dplyr')
trend_data <-
project_pageviews(
project = "en.wikipedia",
end = as.Date("2019-01-01"),
user_type="user"
)
glimpse(trend_data)## Observations: 1,184
## Variables: 7
## $ project <chr> "wikipedia", "wikipedia", "wikipedia", "wikipedia"...
## $ language <chr> "en", "en", "en", "en", "en", "en", "en", "en", "e...
## $ access <chr> "all-access", "all-access", "all-access", "all-acc...
## $ agent <chr> "user", "user", "user", "user", "user", "user", "u...
## $ granularity <chr> "daily", "daily", "daily", "daily", "daily", "dail...
## $ date <dttm> 2015-10-01, 2015-10-02, 2015-10-03, 2015-10-04, 2...
## $ views <dbl> 238845634, 234121441, 221478394, 244396567, 259720...Now we prepare to feed the data to Prophet by simplifying it to a ‘ds’ (date) and a ‘y’ column.
input <- trend_data %>%
rename(
ds = date,
y = views
) %>%
select(ds,y)
str(input)## 'data.frame': 1184 obs. of 2 variables:
## $ ds: POSIXct, format: "2015-10-01" "2015-10-02" ...
## $ y : num 2.39e+08 2.34e+08 2.21e+08 2.44e+08 2.60e+08 ...The parameter we’ll be observing is called the changepoint.prior.scale. The documentation states this is the: “Parameter modulating the flexibility of the automatic changepoint selection. Large values will allow many changepoints, small values will allow few changepoints”. When I read this I had no idea what this meant practically. I think all documentation should have a “this is what that means for you” translation. In order to see what this does, we will be running a lot of different forecasts with different values of this parameter passed in to observe what happens.
Step 2: Generate a lot of forecasts with different values
We will go through a similar process of generating a new forecast every day, but we will multiply the number of forecasts per day by using several different values of changepoint.prior.scale. The package author suggests “a starting range for a search would probably be [0.001, 1]. Depending on how many changepoints were specified, 1 would likely be effectively unregularized”. Based on this we’ll choose the following values: c(0.001,0.01,0.05,0.5)
First, we need to prep the data as we did before, creating a nested dataframe that contains a forecast_date, and then a cell with the nested values of all prior days available.
input$ds <- as.Date(input$ds)
datelist <- seq(from=as.Date('2017-01-01'), to=as.Date(max(input$ds)), by = 'day') %>%
data.frame() %>%
rename(forecast_date='.') %>%
mutate(forecast_date = as.factor(forecast_date))
historical_dates <- input %>%
mutate(ds=as.factor(ds)) %>%
select(ds) %>%
unique()
full_dates <- expand.grid(
datelist$forecast_date,
historical_dates$ds
) %>%
rename(
forecast_date = Var1,
ds = Var2
) %>%
mutate(
forecast_date = as.Date(forecast_date),
ds = as.Date(ds)
)
full_dates <- full_dates[full_dates$forecast_date >= full_dates$ds,]
full_dates <- full_dates %>%
left_join(input, by='ds')
full_dates %<>%
group_by( forecast_date) %>%
tidyr::nest()
names(full_dates) <- c('forecast_date','model_data')
head(full_dates)## # A tibble: 6 x 2
## forecast_date model_data
## <date> <list>
## 1 2017-01-01 <tibble [459 × 2]>
## 2 2017-01-02 <tibble [460 × 2]>
## 3 2017-01-03 <tibble [461 × 2]>
## 4 2017-01-04 <tibble [462 × 2]>
## 5 2017-01-05 <tibble [463 × 2]>
## 6 2017-01-06 <tibble [464 × 2]>We can pass in the different values for changepoint.prior.scale using a column in the dataframe. So we can take the full_dates dataframe and cross join it on the values we want to pass in to get the dataframe fully prepared. CJ from the data.tables package does a cross join
library('data.table')
# cp_values <- c(0.001,0.01,0.05,0.5)
cp_values <- c(0.001,0.01)
forecast_input <- CJ(full_dates$forecast_date, cp_values) %>% data.frame()
names(forecast_input) <- c('forecast_date','cpps')
forecast_input <- forecast_input %>% full_join(full_dates, by = 'forecast_date')Then we declare a function to call Prophet with a variable to toggle the changepoint.prior.scale value.
prophet_call <- function(df, cpps) {
prophet(df=df, changepoint.prior.scale=cpps)
}library( 'future')
library( 'purrr')
library( 'furrr')
library( 'magrittr')
library( 'prophet')
future::plan(multiprocess)
forecast_input %<>%
mutate(
model = furrr::future_map2(model_data, cpps, prophet_call)
)# Create empty future dataframe and predict
plan(multiprocess)
forecast_input <- forecast_input %>%
dplyr::mutate(
future = purrr::map(model, ~make_future_dataframe(., periods = 365))
, future = furrr::future_map2(model, future, predict)
)forecast_df <- forecast_input %>%
select(forecast_date, cpps, future) %>%
tidyr::unnest() %>%
select(forecast_date, cpps, ds, yhat, yhat_upper, yhat_lower) %>%
mutate(ds=as.Date(ds)) %>%
left_join(input, by='ds')error_df <- forecast_df %>%
group_by( forecast_date, cpps) %>%
arrange( ds) %>%
mutate(
in_error_window = between( ds - forecast_date, 1, 30)
, error = abs( ifelse( in_error_window, yhat/y-1, NA))
) %>%
group_by( forecast_date, cpps, in_error_window) %>%
mutate(
mape_30d = mean(error)
) %>%
ungroup() %>%
filter(in_error_window) %>%
group_by(forecast_date, cpps) %>%
summarise(mape_30d = max(mape_30d))
library( 'ggplot2')
ggplot(
error_df
, aes(x=forecast_date, y = mape_30d, color = as.factor(cpps))
) +
geom_line() +
labs(title="Prophet's 30d MAPE on en.wikipedia.org Pageviews", color = 'changepoint.prior.scale') +
scale_y_continuous(labels = scales::percent) +
scale_x_date(date_breaks = '1 months', date_labels = '%b %y') +
theme(axis.text.x = element_text(angle=45, hjust=1), axis.title=element_blank(), panel.grid.major = element_line(color='grey',linetype=2), legend.position='top')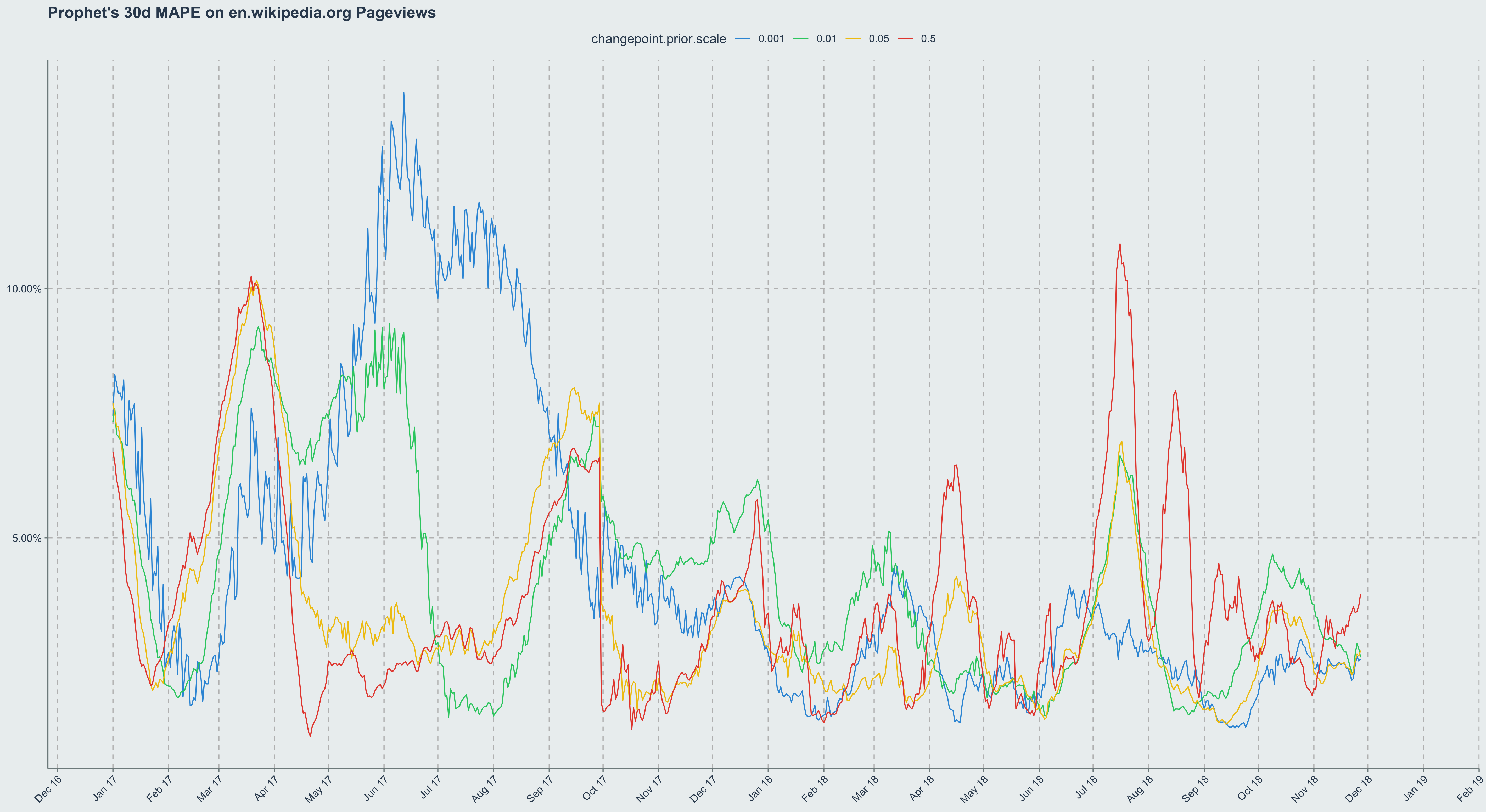
Step 3: Make A Pretty gif Of This With gganimate
Now let’s make a gif of our forecast through time, partitioned by the forecast_date field!
This long-term view is great because you can see where the yearly.seasonality=TRUE kicks in around October 2017.
forecast_plot <- ggplot(
forecast_df %>% filter(
ds >= '2017-01-01'
, cpps != 0.5
)
, aes(
x = ds
, group=forecast_date
)
) +
facet_wrap(~cpps) +
geom_ribbon(
data = forecast_df %>%
filter(
ds >= forecast_date
, cpps != 0.5
)
, aes(ymin=yhat_lower/1e6, ymax=yhat_upper/1e6)
, fill='black'
, alpha = 0.5
) +
geom_line(
aes( y = yhat/1e6)
, color = 'tomato'
, linetype = 2
, alpha=0.3
) +
geom_line(
data = forecast_df %>%
filter(
ds >= '2017-01-01'
, ds <= forecast_date
, cpps != 0.5
)
, aes( y = y/1e6)
) +
scale_x_date(date_breaks = '1 month', date_labels='%b %y') +
theme(axis.text.x=element_text(angle=45, hjust = 1)) +
labs(
title = 'Wikipedia Pageviews (MM) Forecast as of Date: {frame_time}'
, subtitle='Faceted by `changepoint.prior.scale` values'
, x = element_blank()
, y = element_blank()
) +
transition_time(forecast_date) +
ease_aes('linear')
gganimate::animate(forecast_plot, width = 800, height = 450)
data.frame(stringsAsFactors=FALSE, is_strategic_publisher = c(“FALSE”, “FALSE”, “Strategic Publisher”, “Strategic Publisher”, “FALSE”, “FALSE”, “Strategic Publisher”, “Strategic Publisher”, “FALSE”, “FALSE”, “Strategic Publisher”, “Strategic Publisher”, “FALSE”), is_price_target_gkd = c(“FALSE”, “Price Target GK”, “FALSE”, “Price Target GK”, “FALSE”, “Price Target GK”, “FALSE”, “Price Target GK”, “FALSE”, “Price Target GK”, “FALSE”, “Price Target GK”, “FALSE”), is_instant_game = c(“FALSE”, “FALSE”, “FALSE”, “FALSE”, “Instant Game”, “Instant Game”, “Instant Game”, “Instant Game”, “FALSE”, “FALSE”, “FALSE”, “FALSE”, “Instant Game”), is_on_deal = c(“FALSE”, “FALSE”, “FALSE”, “FALSE”, “FALSE”, “FALSE”, “FALSE”, “FALSE”, “On Special Deal”, “On Special Deal”, “On Special Deal”, “On Special Deal”, “On Special Deal”), revenue = c(3098973.839, 134344.5206, 389442.3291, 63739.7426, 526481.4639, 104.4025, 43107.5236, 107.7166, 1183066.049, 40502.7935, 297819.8632, 47412.4123, 184.7481), plcmnt_block_rev = c(351531.4012, 5207.870338, 43937.98183, 378.708137, 80211.25638, 101.433881, 1658.179125, 80.106454, 14686.34642, 20.331771, 21327.00827, 215.032453, 2.727782), junk_plcmnt_rev = c(518539.5493, 5957.97372, 44824.17004, 1681.38089, 76094.51516, 54.38616, 1059.78123, 80.10645, 21263.54786, 92.18246, 44827.10941, 927.56042, 17.72442), junk_bundle_rev = c(371317.8251, 6256.35166, 37220.02662, 129.05396, 51844.0761, 4681.92585, 774.5724, 84.6493, 53949.75611, 4677.72274, 31801.47748, 78.82074, 0), num_bundles = c(13050L, 137L, 314L, 43L, 1903L, 10L, 27L, 2L, 1214L, 35L, 106L, 34L, 2L) )